
cowrie konfigurieren und Daten visualisieren
Im vorangegangen Beitrag habe ich beschrieben wie man cowrie installiert und darauf hingewiesen, dass die Standardkonfiguration nur bedingt sinnvoll ist. Deswegen geht es in diesem Post darum, wie man die Konfiguration von cowrie anpassen kann. Um die Daten aus dem Honeypot zu visualisieren, werden wir die Daten aus cowrie in einen ELK Stack überführen. Aber dazu weiter unten mehr.
Die Konfiguration findet man unter cowrie/etc/cowrie.cfg.dist. Da diese Datei von Updates überschrieben werden kann, erstellen wir eine Kopie, welche wir cowrie.cfg nennen. Die cowrie.cfg wird nicht überschrieben und vorrangig behandelt. In dieser Datei können also Änderungen und Ergänzungen vorgenommen werden.
“Vanilla-cowrie” in der Standardkonfiguration ist leicht als Honeypot identifizierbar, da zum Beispiel der Hostname standardmäßig srv04 lautet. Da cowrie ein populäres Tool ist, wäre es ziemlich auffällig den Hostnamen aus der Standardkonfiguration zu verwenden. Daher wird als erstes der hostname geändert.

Weiterhin empfiehlt es sich weitere Nutzer:innen in cowrie hinzuzufügen bzw. den Namen des bestehenden Users zu ändern. Dieser heißt nämlich immer standardmäßig phil, was wie beim Hostnamen den Honeypot recht schnell enttarnen würde. Ändern lässt sich der Name in der Datei cowrie/honeyfs/etc/passwd.
Um den Namen beispielsweise auf Jane zu ändern, geben wir folgenden Befehl ein, während unsere virtuelle Umgebung aktiviert ist (das machen wir mit source cowrie-env/bin/activate):
bin/fsctl share/cowrie/fs.pickle
und dann
mv /home/phil /home/jane
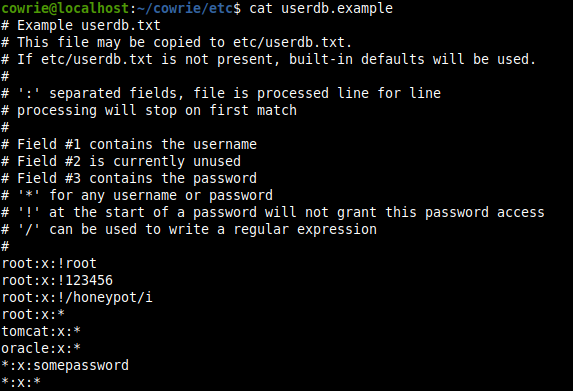
Sinnvoll kann es auch sein die Userdatenbank von cowrie zu konfigurieren. Hier wird festgelegt mit welchen Nutzernamen und Passwörtern sich Angreifer:innen einloggen können.
Eine Beispieldatei userdb.example findet sich unter /cowrie/etc, welche man nach /cowrie/etc/userdb.txt kopieren und anschließend bearbeiten kann.
ELK Stack
Um die Daten, welche uns cowrie liefert zu visualisieren und auszuwerten, installieren wir einen ELK Stack. ELK ist eine Abkürzung für Elasticsearch, Logstash und Kibana. Bei allen drei Tools handelt es sich um Open Source Software. Logstash verarbeitet und transformiert Daten und leitet die Daten an Elasticsearch weiter, welches eine Suchmaschine ist, die sehr schnell große Datenmengen verarbeiten kann. Die Daten innerhalb von Elasticsearch werden mit Kibana visualisiert.
Für den ELK Stack sollte euer Server über ausreichend Ressourcen verfügen. Ich hatte zunächst einen Linode 2GB VPS mit einer CPU und 2 GB Ram. Der Server ist unter der Last des ELK Stacks zusammengebrochen. Daraufhin habe ich dann eine Erweiterung auf eien Linodge 4GB VPS vorgenommen, welcher über 2 CPUs und 4 GB Arbeitsspeicher verfügt. Unter dieser Konfiguration hat es dann funktioniert.
Installation des ELK Stacks
Zunächst installieren wir alle Tools auf unserem Server, auf welchem auch cowrie läuft. Da die Rohdaten als json vorliegen müssen, muss in der cowrie.cfg output_json auf true gesetzt sein. Dies scheint aber standardmäßig schon aktiviert zu sein.
Als erstes müssen wir das Repository und den Key von ElasticSearch hinzufügen.
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | apt-key add -
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | tee /etc/apt/sources.list.d/elastic-7.x.list
apt update
Jetzt können die Tools des ELK Stacks installiert werden. Außerdem installieren wir noch nginx, welchen wir als Reverse Proxy konfigurieren, um auf das Webinterface von Kibana zuzugreifen.
apt -y install apt-transport-https wget default-jre
apt install elasticsearch logstash kibana
apt install nginx apache2-utils
Weiterhin sollte noch filebeat installiert werden, welches Logfiles an Logstash sendet und das System entlastet.
apt install filebeat
Anschließend müssen wir die Dienste aktivieren.
systemctl enable elasticsearch logstash kibana nginx filebeat
und starten
systemctl start elasticsearch logstash kibana filebeat
Elasticsearch verwendet Port 9200. Um zu testen, ob es funktioniert können wir curl http://localhost:9200 eingeben. Als Bestätigung sollte ein JSON Objekt ausgegeben werden.
Kibana
In der Kibana Konfiguration unter /etc/kibana/kibana.yml legen wir einen Servernamen fest und tragen die URL von Elasticsearch ein.

Außerdem tragen wir als logging.dest /var/log/kibana/kibana.log ein.
Filebeat
Filebeat wird so konfiguriert, dass es auf die Logfile von cowrie zugreifen kann. Dazu kopieren wir die dafür vorgesehene Konfiguration ins Verzeichnis von FileBeat.
cp /home/cowrie/cowrie/docs/elk/filebeat-cowrie.conf /etc/filebeat/filebeat.yml"
Die Variable Paths muss auf die JSON Logs von cowrie verweisen. In meiner Beispielinstallation lautet der Pfad /home/cowrie/cowrie/var/log/cowrie/cowrie.json
Siehe dazu auch auch: https://cowrie.readthedocs.io/en/latest/INSTALL.html
Logstash
Die von cowrie vorgegebene Logstash Konfiguration kopieren wir ins Verzeichnis von Logstash.
cp /home/cowrie/cowrie/docs/elk/logstash-cowrie.conf /etc/logstash/conf.d
Zusätzliche sollte die GeoIP Datenbank von MaxMind heruntergeladen werden. Dazu muss man sich kostenlos bei MaxMind registrieren und kann dort die GeoLite2 City Datenbank herunterladen.
Die Datenbank im Format mmdb legen wir unter /opt/logstash/vendor/geoip/ ab.
Anschließend Logstash mit systemctl restart logstash neu starten.
Nginx Reverse Proxy
In der jetzigen Konfiguration ist unser ELK Stack nur über den localhost erreichbar. Damit wir ihn von außerhalb erreichen können, konfigurieren wir einen Nginx Reverse Proxy. Zuerst legen wir einen Nutzer:innenaccount an.
htpasswd -c /etc/nginx/htpasswd.users username
Da sich der Server mit cowrie in meinem Fall nicht in meinem lokalen Netzwerk, sondern in einem Rechenzentrum befindet, habe ich die Verbindung noch mit TLS abgesichert. Da es sich nur um ein Testsystem handelt, habe ich ein selbst signiertes Zertifikat erstellt. Für produktive System sollte man ein ordentlich signiertes Zertifikat von einer anerkannten Certificate Authority verwenden, wie z.B. Let’s Encrypt.
openssl req -x509 -nodes -days 3650 -newkey rsa:2048 -keyout /etc/nginx/cert.key -out /etc/nginx/cert.crt
Die Nginx Konfiguration wird entsprechend angepasst. Zum einen legen wir ein redirect an, damit alle Anfragen auf Port 443 für https weitergeleitet werden. Zum anderen wird Nginx in den Reverse Proxy Modus versetzt, so dass der Server für uns alle Anfragen an Kibana umleitet, welches auf Port 5601 lauscht. Zusätzlich ist Nginx mit einem Username und Passwort abgesichert, welches wir zuvor festgelegt haben.
server {
listen 80;
server_name $IP Adresse;
return 301 https://$server_name$request_uri;
}
server {
listen 443 ssl;
server_name $IP Adresse;
ssl_certificate /etc/nginx/cert.crt;
ssl_certificate_key /etc/nginx/cert.key;
auth_basic "restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
ssl_protocols TLSv1.2;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Konfiguration des Dashboards
Nachdem wir die Grundlagen konfiguriert haben, können wir elastic über https://$IP im Browser aufrufen. Dort klicken wir auf Add your data
Anschließend wählen wir Logstash Logs aus und klicken in dem neuen Fenster unten auf Logstash Logs. Hier muss ein index pattern angelegt werden, damit Kibana weiß, welche Daten ausgewertet werden sollen. In unserem Fall tragen wir den Namen cowrie-logstash-* ein und wählen Timestamp für das Timestamp field aus..

Um die Daten zu visualisieren, muss ein Dashboard erstellt werden. Hier sollte man am besten ein wenig rumspielen und sich das Dashboard nach den eigenen Vorlieben gestalten. Ich habe für den Anfang eine Top-Liste der Usernamen und Passwörter erstellt, mit welchen Angreifer:innen sich versucht haben auf den Server einzuloggen. Außerdem habe ich mit den GeoIP-Daten eine Karte generiert.
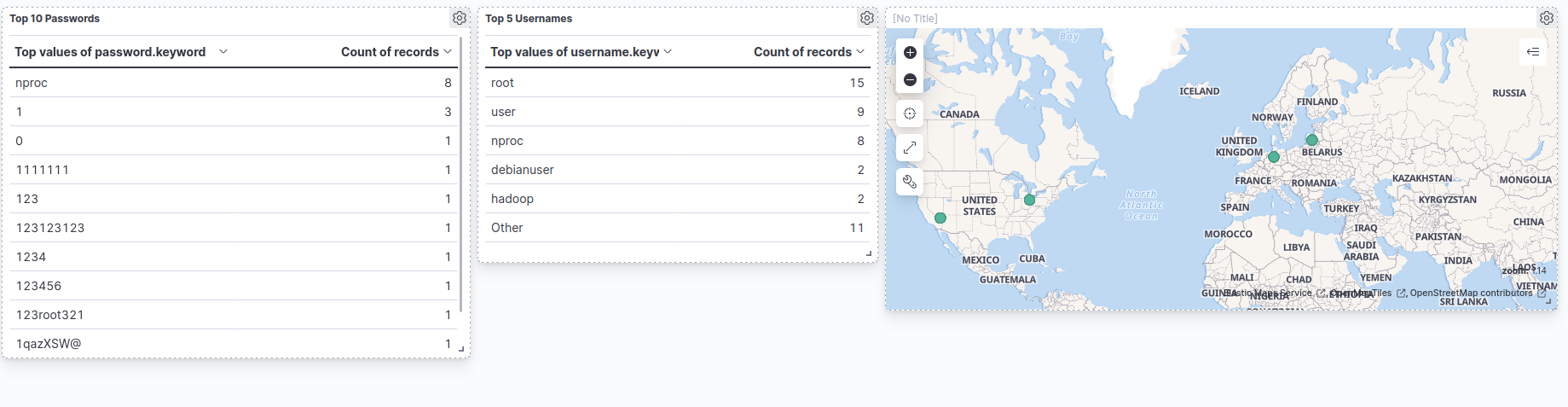
So sah das Dashboard aus, kurz nachdem ich die Konfiguration abgeschlossen hatte. Hier der Screenshot in voller Größe. Was man erkennen kann ist, dass sich vermutlich Bots mit Standardpasswörtern wie 1234 oder 123root321 versuchen haben per SSH einzuloggen. Nach einigen Stunden und ein paar Anpassungen am Dashboard sah es wie folgt aus.
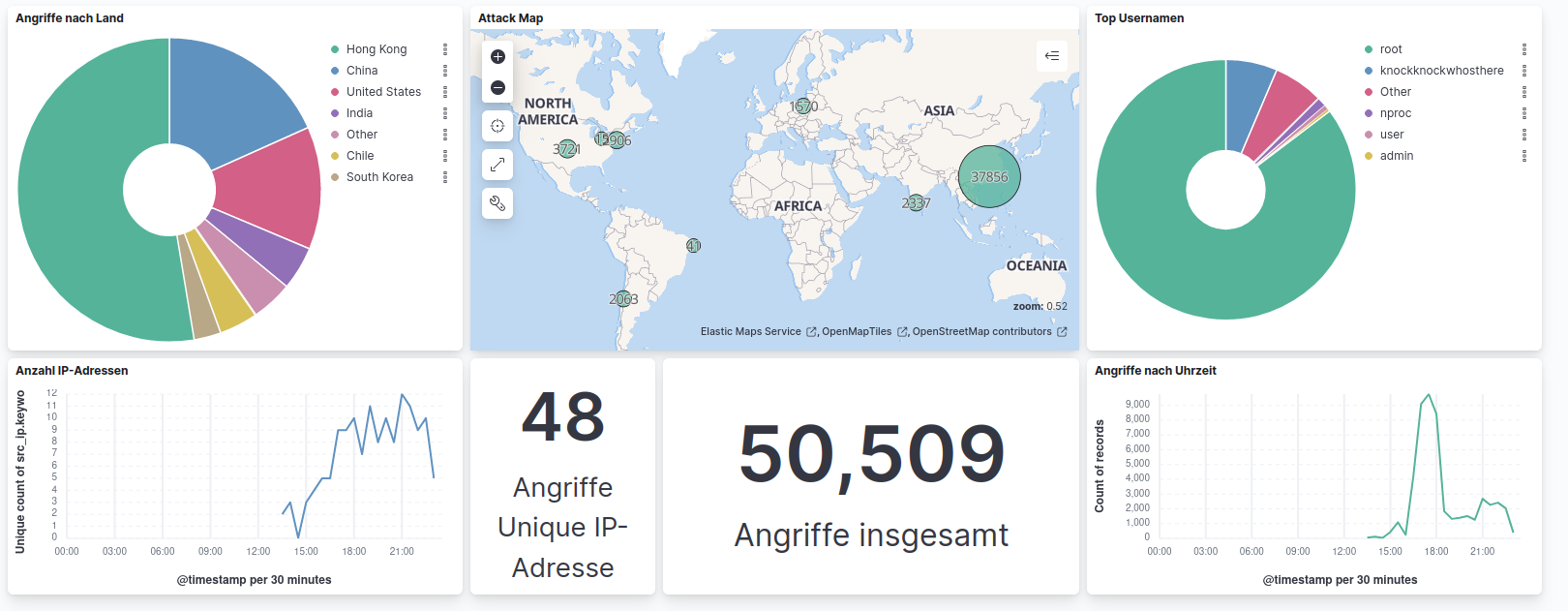
Hier wieder der Screenshot in voller Größe. Innerhalb weniger Stunden erfolgten demnach tausende Angriffsversuche auf den cowrie Honeypot aus unterschiedlichen Ländern. Spannend finde ich vor allem die Visualisierung auf der Karte mit den GeoIP-Daten.
Was ich in dem Beitrag beschrieben habe ist sicherlich nur ein Anfang, da man mit cowrie noch viel mehr Möglichkeiten der Analyse hat und mehr ins Detail gehen kann, um zu verstehen wie Angreifer:innen vorgehen. Eine Beispiel dafür ist, dass man in cowrie hochgeladene Dateien über die VirusTotal API automatisch analysieren lassen kann. Es ist also durchaus lohnenswert selber mal einen Honeypot mit cowrie aufzusetzen und damit zu experimentieren und zu lernen.



